KT AIVLE School/시각지능 딥러닝
MNIST에 CNN 추가, CIFAR-10에 CNN 추가
Rabet
2024. 10. 23. 14:45
MNIST, CIFAR-10
1. 라이브러리 및 데이터 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import random as rd
from sklearn.metrics import accuracy_score
import keras
from keras.utils import clear_session, plot_model
from keras.models import Sequential
from keras.layers import Input, Dense, Flatten, BatchNormalization, Dropout
from keras.layers import Conv2D, MaxPool2D
from keras.optimizers import Adam
from keras.callbacks import EarlyStopping
(train_x, train_y), (test_x, test_y) = keras.datasets.fashion_mnist.load_data() #흑백
(train_x, train_y), (test_x, test_y) = keras.datasets.cifar10.load_data() #컬러
2-1. 스케일링 (흑백)
MinmaxScaling 적용
max_n, min_n = train_x.max(), train_x.min()
train_x = (train_x - min_n) / (max_n - min_n)
test_x = (test_x - min_n) / (max_n - min_n)
train_x = train_x.reshape(-1, 28, 28, 1)
test_x = test_x.reshape(-1, 28, 28, 1)
2-2. 스케일링 (컬러)

standardization 스케일링과 Conv 적용
mean_n, std_n = train_x.mean(), train_x.std()
train_x_ss = (train_x - mean_n) / std_n
test_x_ss = (test_x - mean_n) / std_n
# 채널별 데이터
tr_r_mean, tr_r_std = train_x[:,:,:,0].mean(), train_x[:,:,:,0].std()
tr_g_mean, tr_g_std = train_x[:,:,:,1].mean(), train_x[:,:,:,1].std()
tr_b_mean, tr_b_std = train_x[:,:,:,2].mean(), train_x[:,:,:,2].std()
# 학습 데이터
train_x_r = (train_x[:,:,:,0] - tr_r_mean) / tr_r_std
train_x_g = (train_x[:,:,:,1] - tr_g_mean) / tr_g_std
train_x_b = (train_x[:,:,:,2] - tr_b_mean) / tr_b_std
train_x_ss2 = np.stack((train_x_r, train_x_g, train_x_b), axis=3)
# 테스트 데이터
test_x_r = (test_x[:,:,:,0] - tr_r_mean) / tr_r_std
test_x_g = (test_x[:,:,:,1] - tr_g_mean) / tr_g_std
test_x_b = (test_x[:,:,:,2] - tr_b_mean) / tr_b_std
test_x_ss2 = np.stack((test_x_r, test_x_g, test_x_b), axis=3)
3. 원핫 인코딩
from keras.utils import to_categorical
class_n = len(np.unique(train_y)) #10
train_y = to_categorical(train_y, class_n)
test_y = to_categorical(test_y, class_n)
4. 모델링 및 컴파일
clear_session()
model = Sequential()
model.add( Input(shape=(28, 28, 1)) )
model.add( Conv2D(filters=64, # 새롭게 feature map의 수 or 서로 다른 conv filter 64개 사용
kernel_size = (3,3), # filter의 크기
strides=(1,1), # filter의 움직임
padding='same', # feature map 사이즈 유지
activation='relu'),
model.add( BatchNormalization())
model.add( Conv2D(filters=32,
kernel_size=(3,3),
strides=(1,1),
padding='same',
activation='relu',))
model.add( BatchNormalization())
model.add( MaxPool2D(pool_size=(2,2),
strides=(2,2),))
model.add(Dropout(0.25))
model.add( Conv2D(filters=64,
kernel_size=(3,3),
strides=(1,1),
padding='same',
activation='relu',))
model.add( BatchNormalization())
model.add( Conv2D(filters=64,
kernel_size=(3,3),
strides=(1,1),
padding='same',
activation='relu',))
model.add( BatchNormalization())
model.add( MaxPool2D(pool_size=(2,2),
strides=(2,2),))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(BatchNormalization())
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.summary()
- 모델 다르게 보는법
더보기
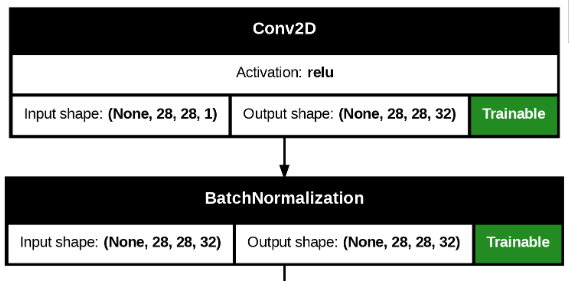
from keras.utils import plot_model
plot_model(model,
show_shapes=True,
show_layer_activations=True,
show_trainable=True,
)
4. 학습하기 (Early Stopping)
batch_size = 32이 기본값
from keras.callbacks import EarlyStopping
es = EarlyStopping(monitor = 'val_loss', # 얼리스토핑의 기준(val_accuracy도 가능)
min_delta = 0, # 임계값보다 크게 변화해야 개선
patience = 5, # 성능 개선이 발생하지 않을 때, 몇 epoch 더 볼 것인가
verbose = 1,
restore_best_weights = True,) # 학습이 멈췄을 때, 최적 가중치 epoch 시점으로 되돌림
hist = model.fit(train_x, train_y, validation_split=0.2,
batch_size = 516,
epochs=10000, verbose=1, callbacks=[es])
5. 학습 결과 확인
- 정확도 확인
plt.figure(figsize=(10, 5))
plt.plot(hist.history['accuracy'])
plt.plot(hist.history['val_accuracy'])
plt.title('Accuracy : Training vs Validation')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Training', 'Validation'], loc=0)
plt.show()
- loss값 확인
plt.figure(figsize=(10, 5))
plt.plot(hist.history['loss'])
plt.plot(hist.history['val_loss'])
plt.title('Loss : Training vs Validation')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Training', 'Validation'], loc=0)
plt.show()
6. 예측하기
y_pred = model.predict(test_x)
single_y_pred = y_pred.argmax(axis=1)
single_test_y = test_y.argmax(axis=1)
test_acc = accuracy_score(single_test_y, single_y_pred)
print(f'테스트셋 정확도 : {test_acc*100:.2f}%' )