- TF- IDF ( Term Frequency-Inverse Document Frequency )
중요한 단어만 먼저 뽑아내는 기법이다.
TF: 현재 문서 중에 단어의 수
IDF : 모든 문서 중 단어가 포함된 문서의 수 (모든 문서에 나오면 특징성이 없기 때문에)

- 단어 표현 ( Word Representation, Word Embedding, Word Vector )
자연어 처리를 위해 텍스트를 벡터로 표현한다. 하나의 벡터는 단어를 표현하는 특징이 된다. (인코딩 과정)
- One-Hot Encoding은 자연어 단어 표현에는 부적합하다.
단점 3가지
1. 단어의 수가 많기에 고차원 저밀도 벡터를 구성한다.
2. 의미나 특성을 표현할 수 없다.
3. 신조어가 생기면 다시 구조를 다시 바꿔야한다는 단점이 있다.
- 유사도
유사도는 동일한 단어를 검색하는데 사용된다.
1. 자카드 유사도
- 두 문장을 각각 단어의 집합으로 만든 뒤 두 집합을 통해 유사도 측정하는 방법이다.
- 즉, 동일한 단어가 몇개인지 특정한다.
- 0~1사이의 값을 가진다.
import numpy as np
from sklearn.metrics import accuracy_score
print(accuracy_score(np.array([1,3,2]),np.array([1,4,5])))
print(accuracy_score(np.array([1,3,2]),np.array([4,1,5])))
print(accuracy_score(np.array([1,1,0,0]),np.array([1,1,0,2])))
print(accuracy_score(np.array([1,0,1,0]),np.array([1,1,0,2])))
2. 코사인 유사도
- 두 개의 벡터값에서 코사인 각도를 구하는 방법이다.
- -1, 1사이의 값을 가진다.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
sentence=( "오늘은 KT에서 강의하는 날입니다.", "언어지능을 강의할 예정입니다.")
vector = TfidfVectorizer(max_features=100)
vector_result = vector.fit_transform(sentence)
print(cosine_similarity(vector_result[0], vector_result[0])) #[[1.]]
print(cosine_similarity(vector_result[0], vector_result[1])) #[[0.]]
- 비지도 학습
아무것도 모르면서.. 배우려고 하는 머신러닝은 갓 태어난 애기와 같다
머신러닝은 data만을 사용하고 Brute Force를 진행한다. 하지만 AI는 Rule이 있다.
- 지도학습, 교사학습 (Supervised Learning) : 데이터, 레이블이 있음
- 비지도 학습 (Unsupervised Learning) : 데이터는 있음, 레이블이 없음 - 데이터를 통해 코사인 유사도를 재고 레이블을 자기가 만듬
- Classification 분류 VS Clustering 자연적으로 비슷해 보이는 것들끼리 분류
- 강화 학습 (Reinforcement Learning) : 실수와 보상을 통해 학습을 하여 목표를 찾아가는 알고리즘
- 데이터 표현
- Discrete 랭크 VS Continuous 무한한 값
1. Data matrix : p사이즈의 특징을 가지고 있는 n명의 사람을 나타냄
2. dissimilarity matrix : 오브젝트에서 오브젝트와의 거리를 나타냄
- Euclidean Distance : 대각선으로 최단 거리를 나타냄
- Manhattan Distance : 도로를 고려하는 것처럼 직선으로 거리를 나타냄
Minkowski Distance
p가 1이면 맨하튼, 2면 유클리드
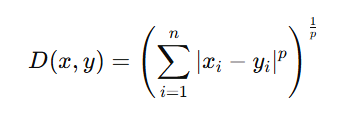
Cosine Measure
0이면 거리가 비슷, 2이면 거리가 다름
1- cos로 유사도 판단함
내적 : 각각의 차이를 구하고 이들을 더하는 것

- Clustering
1. K-means : 100개를 2개로 분류하고 싶을때 두개를 리더로 잡고 가까운 것들을 모여서 평균점에 가까운 표현을 다시 리더로 표현 > 첫번째 시작할때 느림, 4,5개면 안된다..
2. 앙상블 : k-means을 취합하는 과정 combination
- Word Embeding
0곱하기 각각의 다른 값을 구하여 상관관계를 구하는 것
Word2Vec : 텍스트의 단어들 사이의 의미적 유사성을 학습하여, 단어를 고차원 공간에서 벡터로 표현
Input 토끼, Output 야생동물
Input 토끼, Output 애완동물