
이번 미니 프로젝트의 주제는
신규 임대아파트 주차 수요 예측!
토지주택공사의 의뢰를 받아
새롭게 건설할 공공 임대 아파트 단지의 등록 차량수를 예측한다!
는 컨셉으로 시작했습니다ㅎ
마이홈포털
기본팝업-확인 로그인이 필요한 서비스 입니다. 로그인 하시겠습니까? 홈 모집공고 자가진단 지도찾기
www.myhome.go.kr

한국토지주택공사에 데이터를 사용하였기에 신기하면서도 재밌었는데요 :)
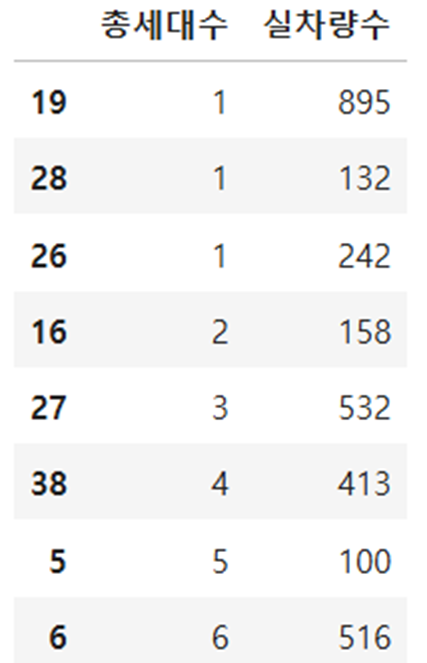
단지코드, 총세대수, 지역, 준공연도, 건물형태, 난방방식, 승강기설치여부, 총면적, 임대보증금, 임대료, 실차량수
위에 총 12개의 변수를 통해서 실차량수(주차 수요)를 예측하게 됩니다.
1. 단변량 분석
- 실차량수, 총세대수, 총면적
유사한 히스토그램을 보이는 것으로 보아 세가지 변수가 강한 상관관계를 가지고 있음을 알 수 있었습니다.
- 준공연도
2003년~2013년(IQR) 동안 전체 345개중에 180개가 지어졌고 아파트가 많이 지어진 기간이 존재했습니다.
이때 당시에 도시 확장이 활발히 이루어 졌다는 것을 예측해볼 수 있었습니다.
- 지역
지역 별 아파트의 수는 경기 > 대구경북 > 광주전남 > 부산울산 순으로 많았고 세종이 2개로 가장 적었습니다.
하지만 세종엔 2개의 아파트 모두 면적이 평균 아파트보다 넓었기에 규모가 매우 컸음을 알 수 있었습니다.
2. 이변량 분석
- 상관관계 분석
실차량수와 상관계수가 높은 변수는 총면적, 총세대수, 면적40_50, 면적50_60, 임대보증금이었고 해당 변수들에 대해 산점도 추가 분석 진행하였습니다.
- 임대 보증금 및 임대료
총면적, 총세대수는 뚜렷한 대각선이 보이는 반면,
임대보증금과 임대료는 대각선이 보이나 신뢰구간이 넓어 약한 상관관계를 가진다고 보았습니다.
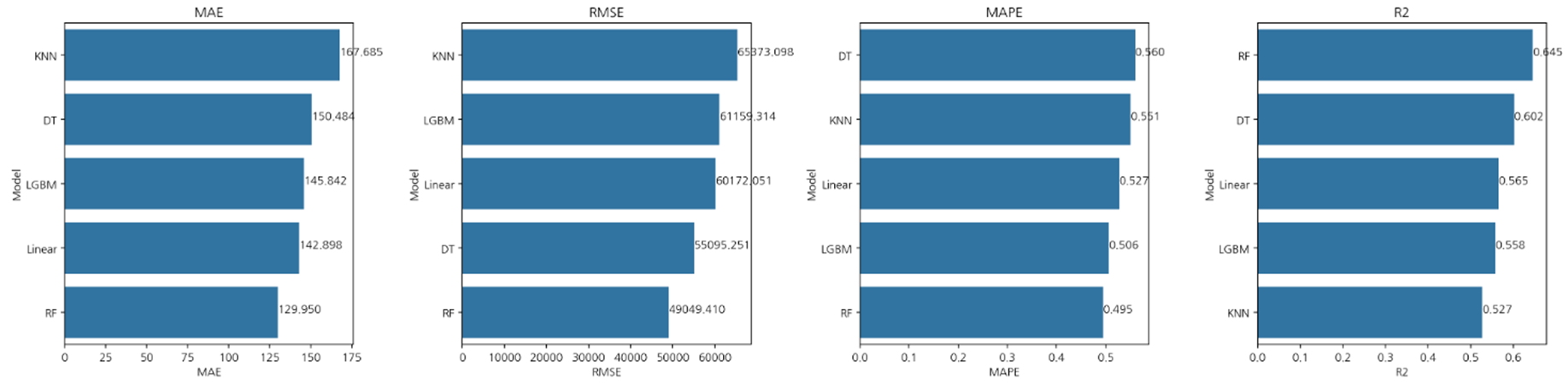
3. 데이터 선정 및 모델링
총세대수 대비 실차량수가 2배 이상 차이가 나는 이상치 데이터가 41개가 있었기에
이를 제거하고 단지내주차면수 데이터를 추가하여 진행한 결과
del_cols = apt01.loc[(apt01['총세대수'] <= 100) & (apt01['실차량수'] - apt01['총세대수'] * 2 > 0)].index
apt01.drop(del_cols, inplace=True)
기본 전처리보다 정확도가 확연히 올라온 것을 볼 수 있습니다.
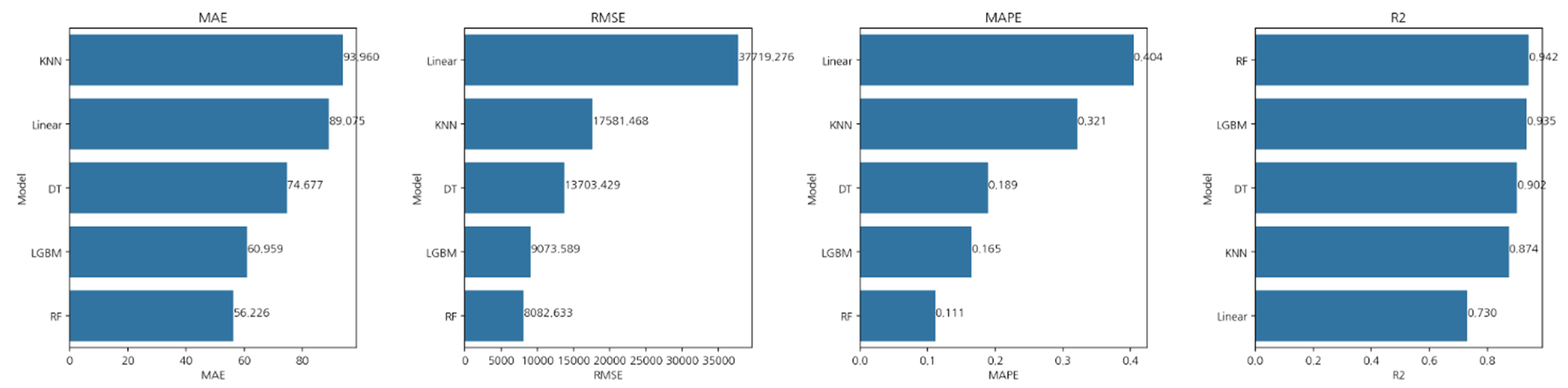
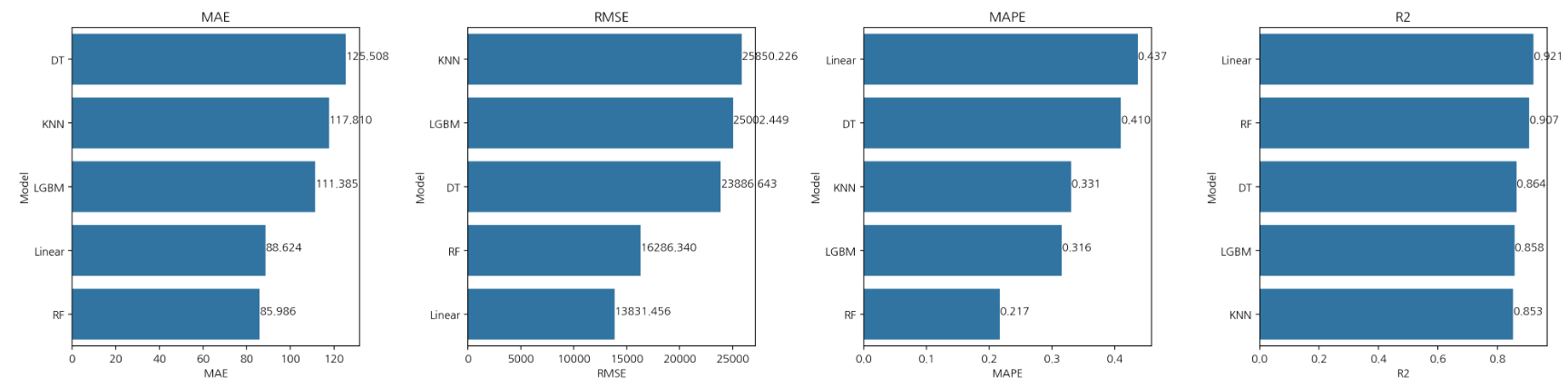
4. 종합 결과
준공연도, 면적80_200, 면적 70_80, 면적50_60, 총세대수, 단지내주차면수, 총면적를 통해
score가 제일 높게 나온 Random Forest를 최종 모델로 선정하였으며
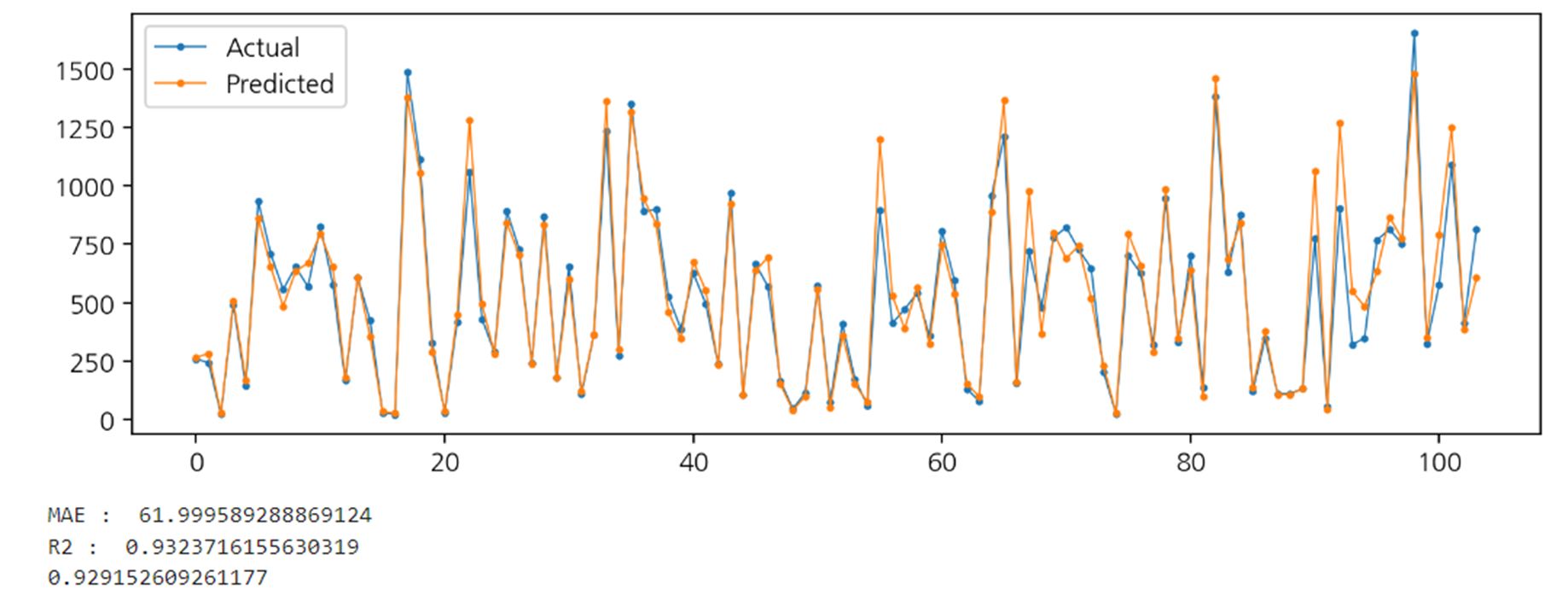
결과적으로 Param 값을 {'max_depth': 10, 'n_estimators': 50}로 잡고 진행하였을 때,
R2 스코어값이 약 0.93라는 높은 정확도를 얻을 수 있었습니다.
5. 느낀점
상관계수가 적은 변수(승강기설치여부, 건물형태, 면적)를 빼고 진행을 해보았을 때,
Linear는 0.92, RandomForest는 0.90이 나왔지만 더욱 높은 정확도를 가지는 머신러닝을 찾기 위해
유의미한 데이터를 찾아보며 팀원들과 함께 진행했던 시간들이 재밌었습니다!
(추가)
미니 프로젝트가 끝난 후에 스터디원들과 함께 진행했던 과제를 공유하는 시간을 가졌습니다ㅎ
교수님께서 주셨던 과제를 그대로 했던 저와 다르게
데이터에 있는 이상치와 의미에 대해 생각해보시는 부원들의 대화에서
데이터 분석이 중요하다는 것을 알게되었고
오프라인, 역할분담, 분석 방식이 궁금했는데 각기 다 다르고
물어볼 수 있는 스터디원분들이 있음에 감사함을 느꼈습니다 :)
'KT AIVLE School > 프로젝트' 카테고리의 다른 글
| [KT AIVLE SCHOOL - 6기 기자단] 빅프로젝트 후기 (0) | 2025.02.25 |
|---|---|
| 응급상황 인식 및 응급실 연계 서비스 포탈 (5) | 2024.12.26 |
| Colab에서 음성파일 만들기 (0) | 2024.11.19 |
| K-DT 해커톤 참여 (1) | 2024.09.30 |
| 1차 미니 프로젝트 후기 (1) | 2024.09.26 |