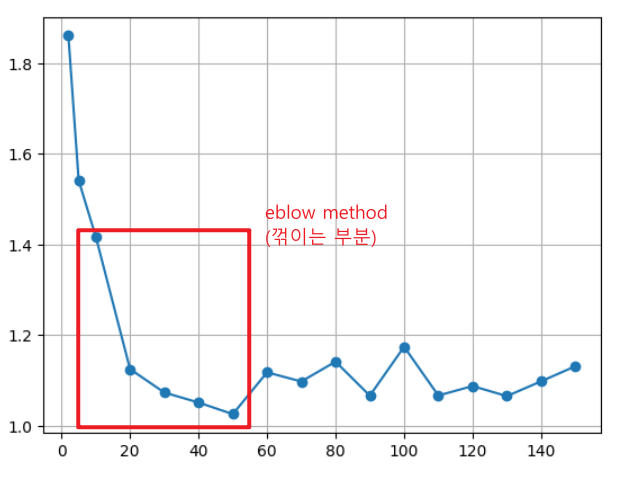
모델의 복잡도 : 학습용 데이터의 패턴을 반영하는 정도
적절한 복잡도가 있어야하고 보통 eblow method에서 끊는다.
1. Epoch와 learning_rate
model.compile(optimizer=Adam(learning_rate = 0.01), loss = 'mse')
model.fit(x_train, y_train, epochs = 50, verbose = False)
2. 모델 구조
from tqdm import tqdm
2-1. hidden layer 수
def modeling_test1(node) :
# 노드 수를 입력 받아 모델 선언
clear_session()
model = Sequential([Input(shape = (nfeatures,)),
Dense(node, activation = 'relu' ),
Dense(1) ] )
model.compile(optimizer=Adam(learning_rate = 0.01), loss = 'mse')
model.fit(x_train, y_train, epochs = 50, verbose = False)
pred = model.predict(x_val)
mae = mean_absolute_error(y_val, pred)
# mae 결과 return
return mae
nodes = [2, 5, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130, 140, 150]
result = []
for n in tqdm(nodes) :
result.append(modeling_test1(n))
# 그래프
plt.plot(nodes, result, marker = 'o')
plt.grid()
plt.show()

2-2. node 수
def modeling_test2(layer) :
# 레이어 리스트 만들기
# 레이어 수 만큼 리스트에 레이어 추가
clear_session()
# 첫번째 레이어는 input_shape가 필요.
layer_list = [Input(shape = (nfeatures,)), Dense(10, activation = 'relu' )]
# 주어진 레이어 수에 맞게 레이어 추가
for i in range(2, layer) : # 첫번째 레이어, 아웃풋 레이어는 명시적으로 추가하므로 2부터 시작
layer_list.append(Dense(10 , activation = 'relu' ))
# Output Layer 추가하고 모델 선언
layer_list.append(Dense(1))
model = Sequential(layer_list)
# 레이어 잘 추가된 건지 확인하기 위해 summary 출력
print(model.summary())
model.compile(optimizer=Adam(learning_rate = 0.01), loss = 'mse')
model.fit(x_train, y_train, epochs = 50, verbose = False)
pred = model.predict(x_val)
mae = mean_absolute_error(y_val, pred)
return maelayers = list(range(1,11))
result = []
for l in tqdm(layers) :
result.append(modeling_test2(l))
# 그래프
plt.plot(layers, result)
plt.grid()
plt.show()
3. Early Stopping
- 라이브러리
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.metrics import *
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense, Flatten, Input
from keras.backend import clear_session
from keras.optimizers import Adam
from keras.datasets import mnist
- Early Stopping : 미리 멈추기
- monitor : 기본값
- min_delta : 오차가 개선되는 양이 최소 몇이 여야 하는지?
- patience : 오차가 줄어들 지 않는 상황 몇번(epochs) 기다려줄지 지정
- restore_best_weights = True : 최적의 가중치를 가진 epoch 시점으로 되돌림
- fit 안에서 지정
- callbacks : epoch 단위로 학습하는 동안 중간에 개입할 task 지정
from keras.callbacks import EarlyStopping# 모델 선언
clear_session()
model2 = Sequential( [Input(shape = (nfeatures,)),
Dense(128, activation= 'relu'),
Dense(64, activation= 'relu'),
Dense(32, activation= 'relu'),
Dense(1, activation= 'sigmoid')] )
model2.compile(optimizer= Adam(learning_rate = 0.001), loss='binary_crossentropy')
# EarlyStopping 설정 ------------
es = EarlyStopping(monitor = 'val_loss', min_delta = 0.0001, patience = 10, restore_best_weights=True)
# --------------------------------
# 학습
hist = model2.fit(x_train, y_train, epochs = 100, validation_split=0.2,
callbacks = [es]).history
dl_history_plot(hist)
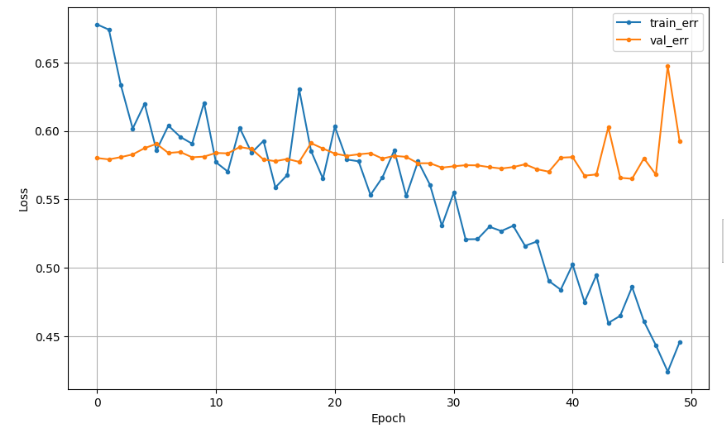
4. Dropout
Dropout : 규제 기법 중 하나 - 신경망의 일부 뉴런을 임의로 비활성화 (모델을 강제로 일반화)
은닉층 사이에 Dropout Layer 추가
은닉층 노드 중에서 40%를 임의로 제외시킴
하이퍼파라미터 튜닝 : val성능을 보면서 사람이 조정해야 되는 값
from keras.layers import Dropout# 메모리 정리
clear_session()
# Sequential 타입
model3 = Sequential( [Input(shape = (nfeatures,)),
Dense(128, activation= 'relu'),
Dropout(0.4),
Dense(64, activation= 'relu'),
Dropout(0.4),
Dense(32, activation= 'relu'),
Dropout(0.4),
Dense(1, activation= 'sigmoid')] )
# 컴파일
model3.compile(optimizer= Adam(learning_rate = 0.001), loss='binary_crossentropy')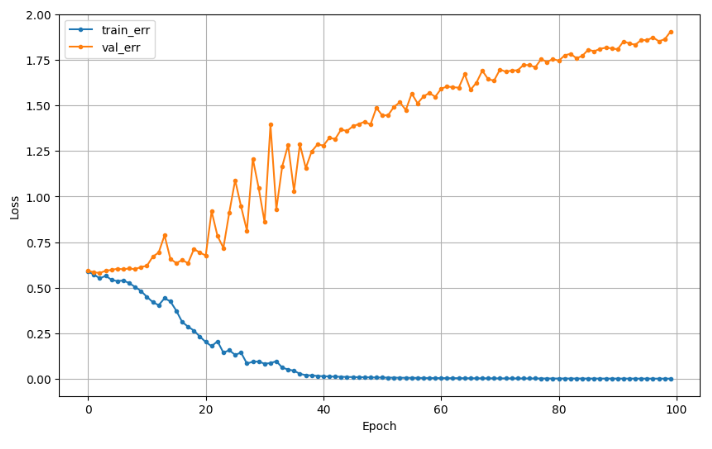
'KT AIVLE School > 딥러닝' 카테고리의 다른 글
| 시계열 모델링 (0) | 2024.10.15 |
|---|---|
| Functional API 및 다중 입력 (0) | 2024.10.15 |
| 모델 저장하기 (0) | 2024.10.14 |
| 분류모델링 (1) | 2024.10.11 |
| 회귀모델링 (1) | 2024.10.11 |