웹 크롤링 순서

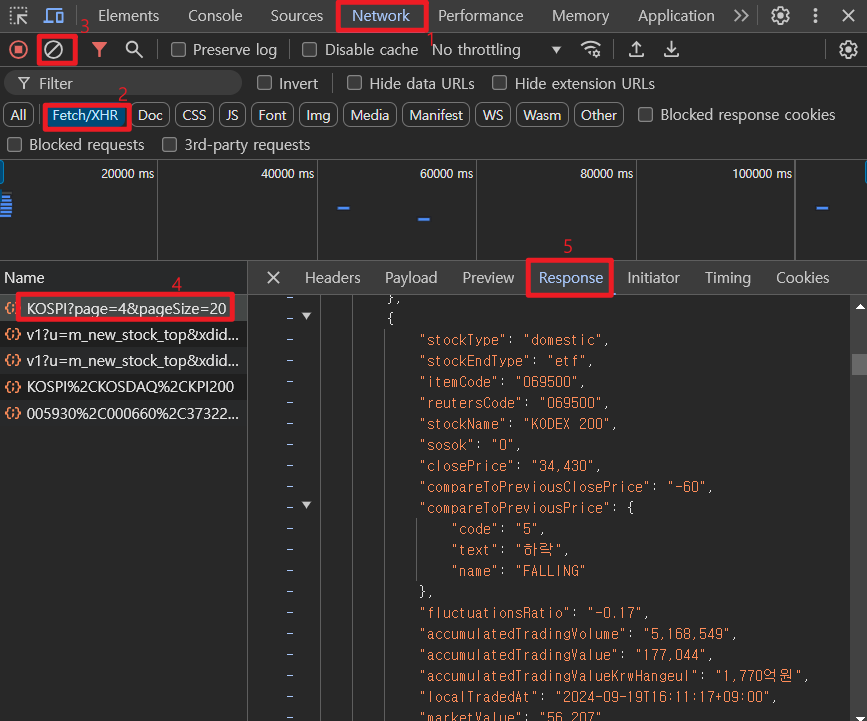
1. URL 찾기 : 웹페이지 분석 (chrome devtools 사용)
2. Request (URL) → Response (Data: JSON이면 동적페이지, HTML이면 정적페이지)
3. Parsing (Data를 DataFrame으로 변환)
- 정적페이지 <p> 123 </p> 형태
- 동적페이지 [1,2,3] 형태
데이터 수집 세부 순서
모두 처음엔 URL을 통해 html을 가져온다.

- 동적페이지 :
웹 브라우져에 화면이 한번 뜨면 이벤트에 의한 화면의 변경이 없는 페이지
1. Devtools를 통해 URL을 가져온다.
2. Request(url) > Response(str>JSON)
3. JSON(str) > list, dict > DataFrame
- 정적페이지
웹 브라우져에 화면이 뜨고 이벤트가 발생하면 서버에서 데이터를 가져와 화면을 변경하는 페이지
1. Devtools를 통해 URL을 가져온다.
2. Request(url) > Response(str>HTML)
3. HTML(str) > BS4 패키지(CSS-Selector) > text > list, dict > DataFrame
- Selenim
브라우져를 직접 열어서 데이터를 받는 방법
네이버 증권 사이트 : 동적 페이지 Crawling
import requests
import pandas as pd
1. 웹서비스 분석 URL
page_size, page = 60, 1
url = f'https://m.stock.naver.com/api/index/KOSPI/price?pageSize={page_size}&page={page}'- url 찾기

- 개발자 도구로 기사 사기치는 법
1. f12 > 위에 버튼 누르고 바꾸고 싶은 기사 클릭
2. html에서 글씨 변경 후 Enter


2. 서버에 데이터 요청 : requests.get(url) > response( json(str) )
response = requests.get(url)
response #<Response [200]>
# 타입 확인법
type(response)
type(response.text)
# 텍스트 확인
response.text[:100]
3. 서버에서 받은 데이터 파싱(데이터 형태를 변경) : json > dict > DataFrame
data = response.json()
#type(data), data[:2]
df = pd.DataFrame(data)
df = df[['localTradedAt', 'closePrice']] # 필요한 데이터 불러오기
df.tail(2)
4. 함수로 생성
- KOSPI, KOSDAC
def stock_price(code='KOSPI',page=1, page_size=60):
url = f'https://m.stock.naver.com/api/index/{code}/price?pageSize={page_size}&page={page}'
response = requests.get(url)
data = response.json()
return pd.DataFrame(data)[['localTradedAt', 'closePrice']]
kp_df = stock_price('KOSPI', page_size=page_size)
kd_df = stock_price('KOSDAQ', page_size=page_size)
- 환율 데이터(result만 출력)
def exchange_rate(code='FX_USDKRW',page=1, page_size=60):
url = f'https://m.stock.naver.com/front-api/marketIndex/prices?\
category=exchange&reutersCode=FX_USDKRW&page={page}&pageSize={page_size}'
response = requests.get(url)
data = response.json()['result']
return pd.DataFrame(data)[['localTradedAt', 'closePrice']]
usd_df = exchange_rate(page_size=page_size)

5. 시각화
# 데이터 수집
page_size = 30
kp_df = stock_price('KOSPI', page_size=page_size)
kd_df = stock_price('KOSDAQ', page_size=page_size)
usd_df = exchange_rate(page_size=page_size)
# 데이터 전처리
# data=response.json()
kp_df['closePrice'] = kp_df['closePrice'].apply(lambda data: float(data.replace(',', '')))
kd_df['closePrice'] = kd_df['closePrice'].apply(lambda data: float(data.replace(',', '')))
usd_df['closePrice'] = usd_df['closePrice'].apply(lambda data: float(data.replace(',', '')))import matplotlib.pyplot as plt
plt.figure(figsize=(15,5))
plt.plot(kp_df['localTradedAt'], kp_df['closePrice'],label='kospi')
plt.plot(kd_df['localTradedAt'], kd_df['closePrice'],label='kosdac')
plt.plot(usd_df['localTradedAt'], usd_df['closePrice'],label='usd')
plt.xticks(kp_df['localTradedAt'][::5]) # 날짜 데이터를 5개씩 점프)
plt.legend()
plt.show()
6. 데이터 스케일링
스케일을 맞추는데 사용하는 min, max scaling
예전에도 사용한 적이 있었기 때문에 친숙했다.
데이터의 min, max를 사용하여 데이터를 0하고 1사이로 변경하는 것이다.

from sklearn.preprocessing import minmax_scale
minmax_scale(kp_df['closePrice'])

from sklearn.preprocessing import minmax_scale
plt.figure(figsize=(20, 10))
plt.plot(kp_df['localTradedAt'], minmax_scale(kp_df['closePrice']), label='kospi')
plt.plot(kd_df['localTradedAt'], minmax_scale(kd_df['closePrice']), label='kosdaq')
plt.plot(usd_df['localTradedAt'], minmax_scale(usd_df['closePrice']), label='usd')
plt.xticks(kp_df['localTradedAt'][::5])
plt.legend()
plt.show()
7. 상관관계 분석
- 피어슨 상관계수(Pearson Correlation Coefficient)
- 상관계수의 해석
- -1에 가까울수록 서로 반대방향으로 움직임
- 1에 가까울수록 서로 같은방향으로 움직임
- 0에 가까울수록 두 데이터는 관계가 없음
# 데이터 3개 합치기 : merge
merge_df = pd.merge(kp_df, kd_df, on='localTradedAt')
merge_df = pd.merge(merge_df, usd_df, on='localTradedAt')
merge_df.columns = ['date', 'kospi', 'kosdaq', 'usd']
merge_df.tail(2)
# 시간 데이터(localTradedAt)열 제거
merge_df.iloc[:,1:].corr()


원달러환율이 높으면 달러를 원화로 환전하여 코스피 지수를 구매하고
원달러환율이 낮으면 코스피 지수를 판매하여 달러로 환전해야 함을 알게됨
'KT AIVLE School > 웹크롤링' 카테고리의 다른 글
| ZigBang 원룸 매물 데이터 수집 (1) | 2024.09.20 |
|---|---|
| NAVER API (1) | 2024.09.20 |
| 403 문제가 생겼을 시 (1) | 2024.09.20 |
| Python (0) | 2024.09.19 |
| Web이란? (0) | 2024.09.19 |