Crawling Naver Stock Report : 정적페이지
종목분석 리포트 : 네이버페이 증권
관심종목의 실시간 주가를 가장 빠르게 확인하는 곳
finance.naver.com
- 네이버 증권 > 리서치 > 종목분석 리포트 > +더보기
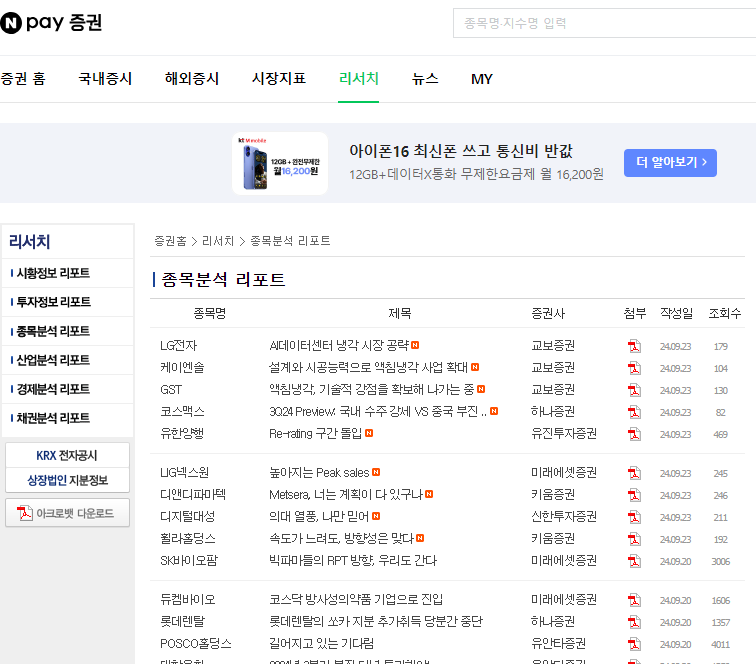
1. url 찾기

- Review와 Response에 내가 필요한 데이터가 있는지 확인, Ctrl+F > LG전자가 있는지 확인

- 코드 작성
import requests
import pandas as pd
from bs4 import BeautifulSoup
page = 1
url = f'https://finance.naver.com/research/company_list.naver?&page={page}'
2. Request로 HTML 받아오기
response = requests.get(url)
response.text[:200]
3. HTML을 BeauitulSoup개체로 css-selector을 활용해 원하는 데이터 불러오기
# 3. HTML > BeautifulSoup > css-selector > DataFrame
dom = BeautifulSoup(response.content, 'html.parser')
dom # dom.select(css-selector), select_one(css-selector)가 가능
- 웹에서 원하는 앨리먼트 찾기
- 오른쪽 클릭 > Copy > Copy Selector
- #contentarea_left > div.box_type_m > table.type_1 > tbody > tr:nth-child(3)

#selector = '#contentarea_left > div.box_type_m > table.type_1> tbody > tr:nth-child(3)'
selector = '#contentarea_left > div.box_type_m > table.type_1> tr'
elements = dom.select(selector)
len(elements) #49
- 만약 Copy Selector로 찾은 selector에 앨리먼트가 없다면?
1. Ctrl + U : 웹에서 페이지 소스 보기

2. 확인하고 바꿔주기
tbody가 개발자 도구에는 있고 실제 소스 코드에서는 없으므로 바꿔주기
selector = 'table.type_1> tr'
elements = dom.select(selector)
elements[2]
#그냥 elements는 49개 다양함
# td테그만 추출
tag = element.select('td')
len(tag), tag


- tag 6개 데이터 추출
data={}
data['stock_name'] = tag[0].select_one('a').text # a 엘리먼트의 text 추가
#data['stock_name'] = tag[0].select('a')[0].text
data['stock_link'] = tag[0].select_one('a').get('href')
data['title'] = tag[1].select_one('a').text
data['title_link'] = tag[1].select_one('a').get('href')
data['writer'] = tag[2].text
data['pdf_link'] = tag[3].select_one('a').get('href')
data['date'] = tag[4].text
data['pv'] = tag[5].text
data
4. List > DataFrame으로 변환
enumerate(데이터) : 데이터에 인덱스 번호를 추가
for idx, element in enumerate(elements): #idx 추가하는 enumerate 함수
tag = element.select('td')
print(idx, len(tag))
- 반복문으로 모든 데이터 가져오기
# enumerate
rows = []
for idx, element in enumerate(elements): #idx 추가하는 enumerate 함수
tag = element.select('td')
if len(tag) == 6:
data={}
data['stock_name'] = tag[0].select_one('a').text
data['stock_link'] = tag[0].select_one('a').get('href')
data['title'] = tag[1].select_one('a').text
data['title_link'] = tag[1].select_one('a').get('href')
data['writer'] = tag[2].text
data['pdf_link'] = tag[3].select_one('a').get('href')
data['date'] = tag[4].text
data['pv'] = tag[5].text
rows.append(data)
rows
df =pd.DataFrame(rows)
df.tail(2)
- 실행코드
import requests
import pandas as pd
from bs4 import BeautifulSoup
page = 1
url = f'https://finance.naver.com/research/company_list.naver?&page={page}'
response = requests.get(url)
dom = BeautifulSoup(response.content, 'html.parser')
selector = 'table.type_1> tr'
elements = dom.select(selector)
element = elements[2]
tag = element.select('td')
rows = []
for idx, element in enumerate(elements): #idx 추가하는 enumerate 함수
tag = element.select('td')
if len(tag) == 6:
data={}
data['stock_name'] = tag[0].select_one('a').text
data['stock_link'] = tag[0].select_one('a').get('href')
data['title'] = tag[1].select_one('a').text
data['title_link'] = tag[1].select_one('a').get('href')
data['writer'] = tag[2].text
data['pdf_link'] = tag[3].select_one('a').get('href')
data['date'] = tag[4].text
data['pv'] = tag[5].text
rows.append(data)
df = pd.DataFrame(rows)
df.tail(3) #30개
5. 파일 다운로드
- 데이터프레임의 0열 파일만 저장해보기
import os : 파일 시스템을 관리하는 파이썬 패키지
# os package : 파일 시스템을 관리하는 파이썬 패키지
import os
path = 'reports'
if not os.path.exists(path): #디렉토리, 파일이 존재하지 않으면
os.makedirs(path)
# url 링크 가져오기
title = df.loc[0,'title']
pdf_link = df.loc[0,'pdf_link']
response = requests.get(pdf_link)
# response
response = requests.get(pdf_link)
# 3. pdf > save(/reports)
filename = f'{path}/{title}.pdf' #reports/AI데이터센터 냉각 시장 공략.pdf
with open(filename, 'wb') as file:
file.write(response.content)
# 파일목록출력
os.listdir('reports')
- 함수로 모두 저장해보기
shutil.rmtree : 파일 삭제
iterrows() : idx를 추가해서 보여줌
# 원래 데이터 삭제
import shutil
path = 'reports'
shutil.rmtree(path)
# 디렉토리 생성
path = 'reports'
os.makedirs(path)
for idx, row in df.iterrows():
#print(idx, row['title'], row['pdf_link'])
print(idx, end=' ')
title , pdf_link = row['title'],row['pdf_link']
response = requests.get(pdf_link)
filename = f'{path}/{title}.pdf'
with open(filename, 'wb') as file:
file.write(response.content)
#0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
os.listdir(path)

'KT AIVLE School > 웹크롤링' 카테고리의 다른 글
| XPath (0) | 2024.09.23 |
|---|---|
| Selenium (3) | 2024.09.23 |
| 정적 페이지 크롤링 (2) | 2024.09.20 |
| ZigBang 원룸 매물 데이터 수집 (0) | 2024.09.20 |
| NAVER API (0) | 2024.09.20 |