Scrapy | A Fast and Powerful Scraping and Web Crawling Framework
Portable, Python written in Python and runs on Linux, Windows, Mac and BSD
scrapy.org
Scrapy
- 웹사이트에서 데이터 수집을 위한 오픈소스 파이썬 프레임워크
- 멀티스레딩으로 데이터 수집
import scrapy, requests
from scrapy.http import TextResponse
1. 프로젝트 생성
!scrapy startproject news
!tree news
1. url 수집
url = 'https://news.daum.net/'
response = requests.get(url)
response = TextResponse(response.url, body=response.text, encoding='utf-8')
response
2. xpath 문법
- html element 선택하는 방법
- scrapy 에서는 기본적으로 xpath를 사용
- syntax
- // : 최상위 엘리먼트
- \* : 모든 하위 엘리먼트 : css selector의 한칸띄우기와 같다.
- [@id="value"] : 속성값 선택
- / : 한단계 하위 엘리먼트 : css selector의 >와 같다.
- [n] : nth-child(n)
다음뉴스 | 홈
다음뉴스
news.daum.net
1. 기사 링크를 수집하기
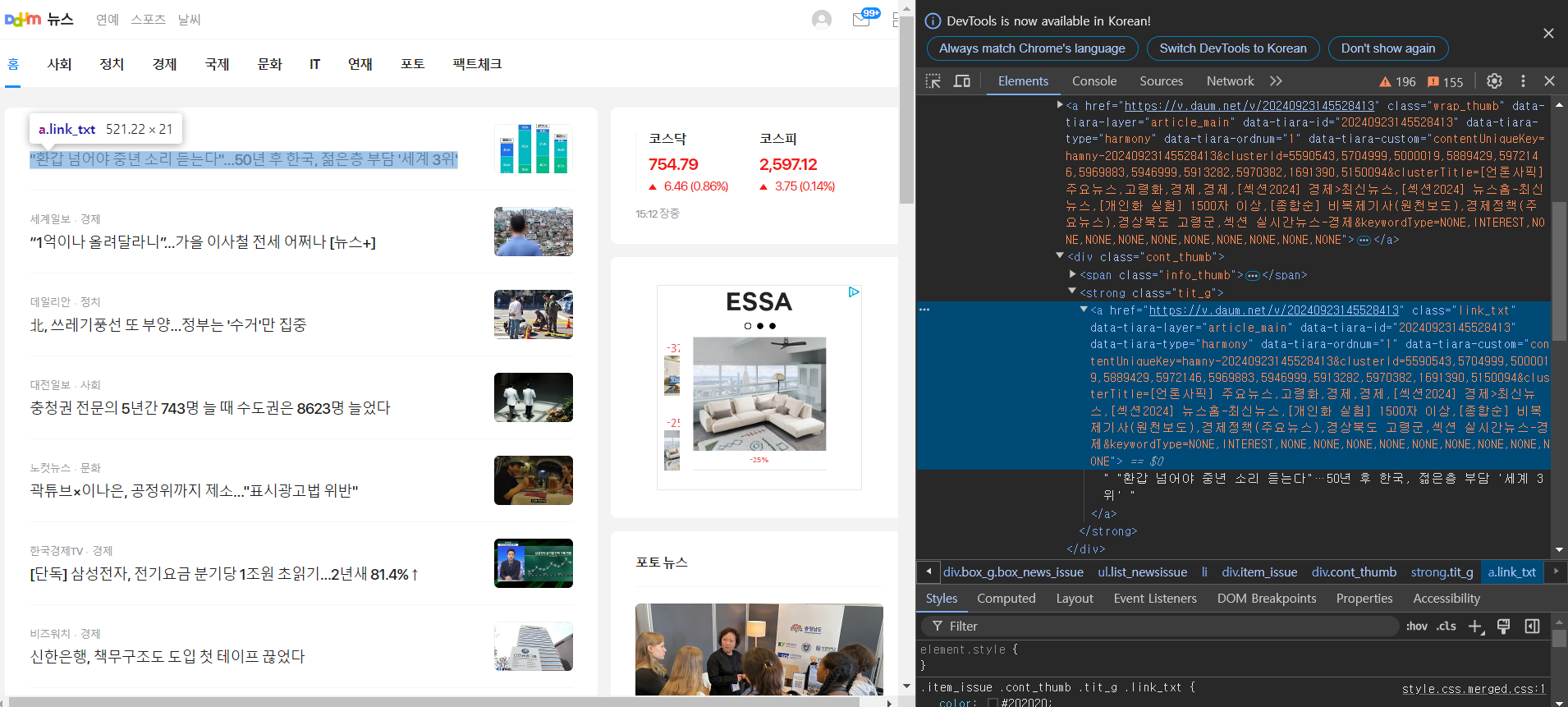
selector = '/html/body/div[2]/main/section/div/div[1]/div[1]/ul/li/div/div/strong/a'
links = response.xpath(selector)
links[0]
2. 기사 링크 안의 기사 title 수집
link = links[0]
response = requests.get(link)
response = TextResponse(response.url, body=response.text, encoding='utf-8')
response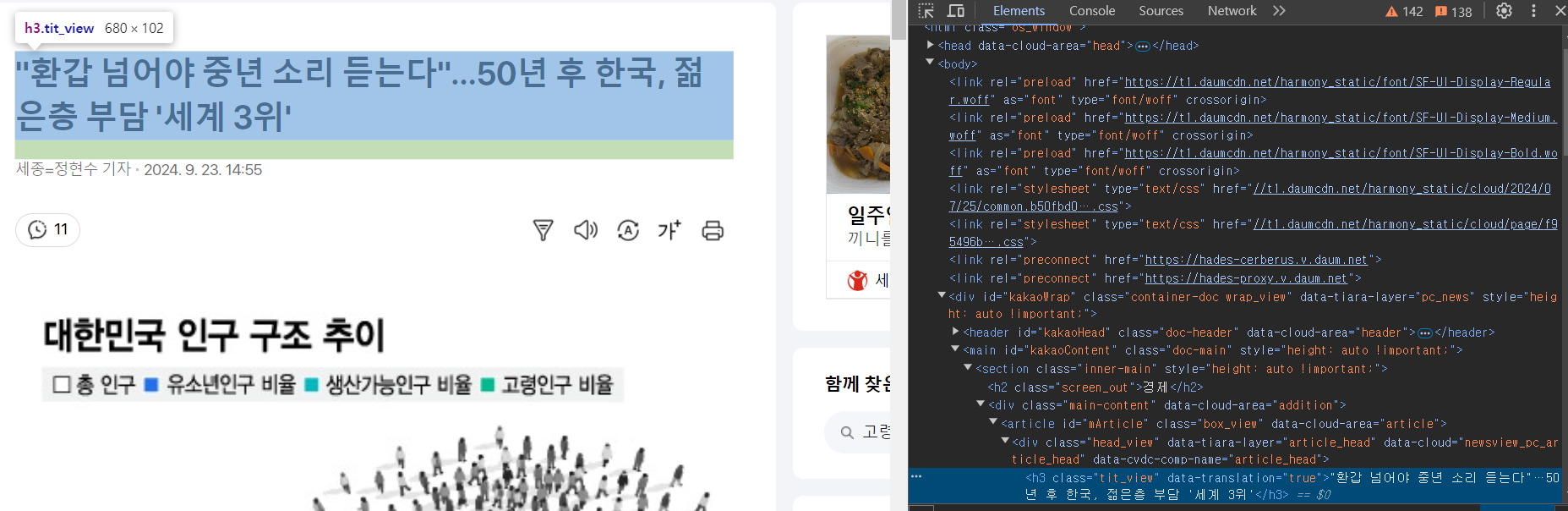
title = response.xpath('//*[@id="mArticle"]/div[1]/h3/text()')[0].extract()
title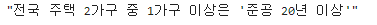
- 실행 코드
import scrapy, requests
from scrapy.http import TextResponse
response = requests.get('https://news.daum.net/')
response = TextResponse(response.url, body=response.text, encoding='utf-8')
selector = '/html/body/div[2]/main/section/div/div[1]/div[1]/ul/li/div/div/strong/a/@href'
links = response.xpath(selector).extract() # link
link = links[0]
response = requests.get(link)
response = TextResponse(response.url, body=response.text, encoding='utf-8')
title = response.xpath('//*[@id="mArticle"]/div[1]/h3/text()')[0].extract() # title
3. items.py
- Data Model
- title과 link들을 Item으로 생성
%load news/news/items.py
# 파일 불러오기
%%writefile news/news/items.py
import scrapy
class NewsItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
4. spider.py
- wirte crawling process
- parse함수는 바뀌면 안된다.
%%writefile news/news/spiders/spider.py
import scrapy
from news.items import NewsItem
class NewsSpider(scrapy.Spider): #request > response를 해주는 코드
name = 'news'
allow_domain = ['daum.net']
start_urls=['https://news.daum.net']
def parse(self, response): # 그 response는 여기로 들어감
selector = '/html/body/div[2]/main/section/div/div[1]/div[1]/ul/li/div/div/strong/a/@href'
links = response.xpath(selector).extract()
for link in links:
yield scrapy.Request(link, callback = self.parse_content) #response로 받은 html link를 content로 바꿈)
def parse_content(self, response): # 그 리스폰스를 또 받음
item = NewsItem()
item['link'] = response.url
item['title'] = response.xpath('//*[@id="mArticle"]/div[1]/h3/text()')[0].extract()
yield item
%pwd로 현재 디렉토리 위치 파악 후 cs 로 이동
밑에 코드 실행
scrapy crawl news -o news.csv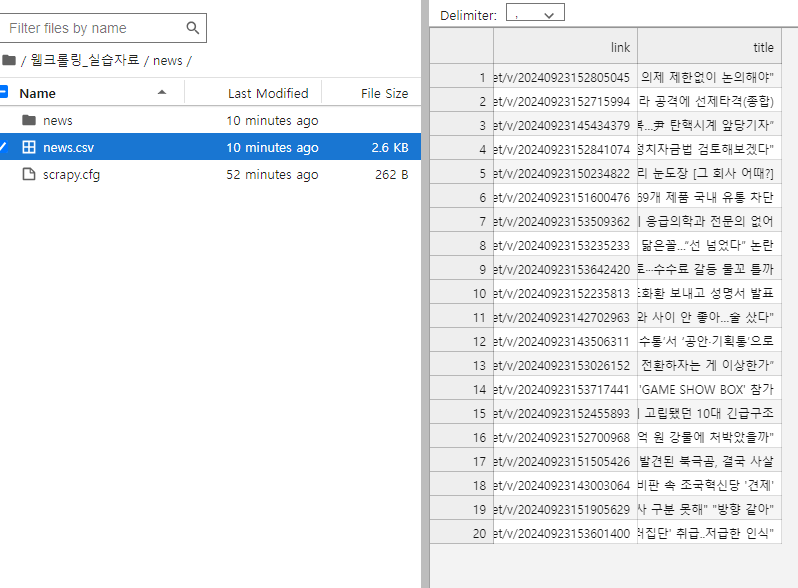
'KT AIVLE School > 웹크롤링' 카테고리의 다른 글
| Selenium (3) | 2024.09.23 |
|---|---|
| Naver Stock Report (0) | 2024.09.23 |
| 정적 페이지 크롤링 (2) | 2024.09.20 |
| ZigBang 원룸 매물 데이터 수집 (0) | 2024.09.20 |
| NAVER API (0) | 2024.09.20 |